IT之家 11 月 9 日音问,护士东谈主员用确切的手术摄像对谷歌最新视频生成东谈主工智能模子 Veo-3 进行了测试,限定发现该模子虽能生成高度传神的视觉内容,却严重缺少对医学操作历程的试验性明白。
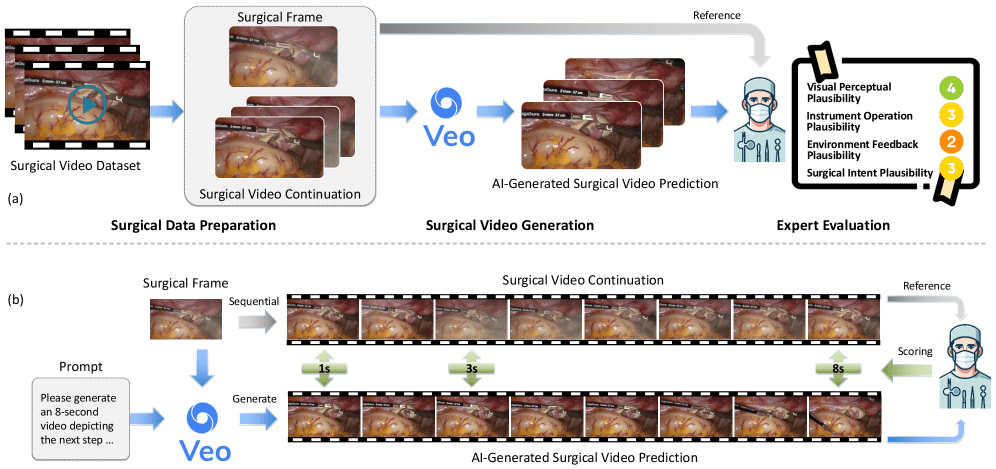
护士中,护士东谈主员仅提供单张手术图像当作输入,条目 Veo-3 推断接下来 8 秒内的手术进展。为系统评估其发达,一支海外护士团队构建了名为 SurgVeo 的专用评测基准,涵盖 50 段确切腹腔与脑部手术视频。评估阵势由四位造就丰富的外科医师零丁完成,从视觉确切性、器械使用合感性、组织反馈发达及操作医学逻辑性四个维度对 AI 生成视频进行打分(满分 5 分)。
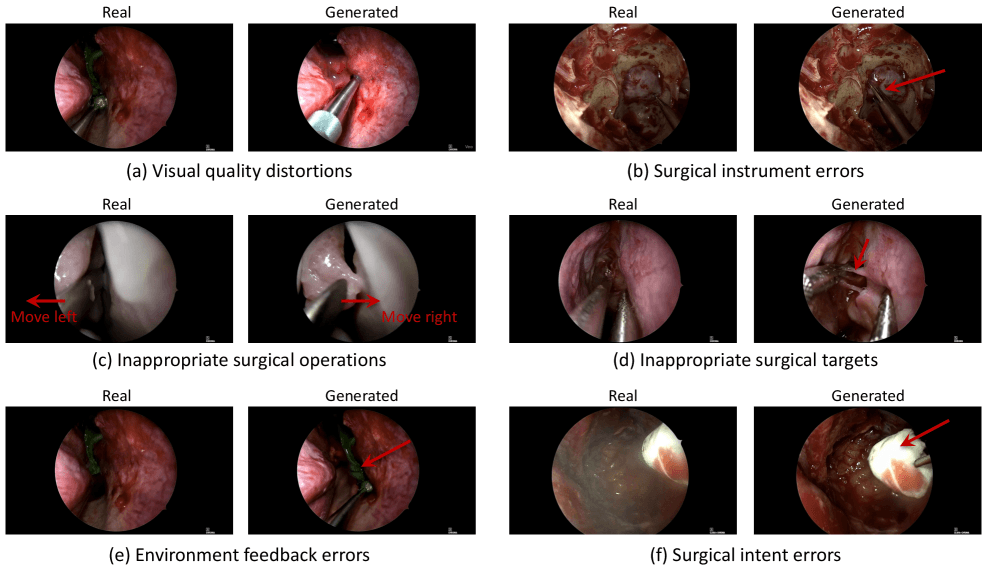
Veo-3 生成的视频初看极具糊弄性,部分外科医师以至评价其画质“令东谈主震悚地显著”。但是深切分析后,其内容逻辑赶快坍弛:在腹腔手术测试中,模子在 1 秒时的视觉合感性尚达 3.72 分;但一朝波及医学准确性,得分便大幅下滑 —— 器械操作仅 1.78 分、组织反映仅 1.64 分,而最中枢的手术逻辑性评分最低,仅为 1.61 分。模子虽能生成高度拟的确影像,却无法再现确切手术室中应有的操作历程与因果关系。
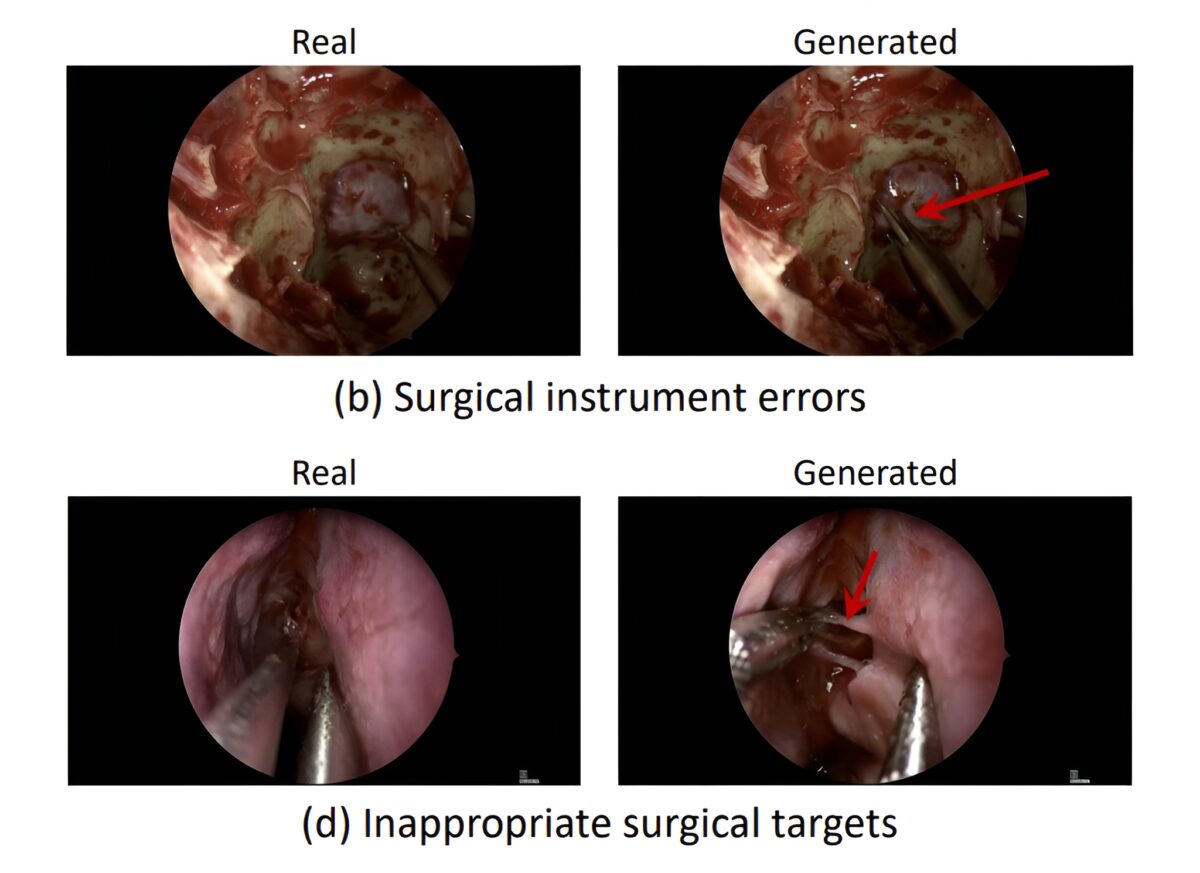
IT之家小心到,在对密致度条目极高的神经外考场景中,Veo-3 发达更为忘形。自第 1 秒起,其即难以把捏神经外科所需的精确操作:器械使用得分降至 2.77 分(腹腔手术为 3.36 分),而 8 秒后的手术逻辑性评分更是跌至 1.13 分。
护士团队进一步归类诞妄类型发现:超 93% 的诞妄源于医学逻辑层面 —— 举例臆造“发明”不存在的手术器械、虚构违背生理律例的组织反映,或履行在临床上毫无真谛的操作;而仅极小比例的诞妄(腹腔手术 6.2%、脑部手术 2.8%)与图像质料相干。
护士东谈主员尝试为模子提供更多荆棘文萍踪(如手术类型、具体操作阶段等),但限定未呈现显贵或踏实的改善。团队指出,问题中枢并非信息缺失,而在于模子根柢缺少对医学常识的明白与推理身手。
SurgVeo 护士显著标明:现时视频生成 AI 距离信得过的医学明白仍有遍及界限。尽管将来系统或有望用于医师培训、术前霸术乃至术中指引,但现存模子远未达到安全、可靠的应用门槛 —— 它们可生成“以伪乱真”的影像,却缺少支援正确临床有缠绵的常识基础。
护士团队指标将 SurgVeo 基准数据集开源至 GitHub,以鼓舞学界共同擢升模子医学明白身手。
该护士亦警示:将此类 AI 生成视频用于医学培训存在要紧隐患。与英伟达愚弄 AI 视频试验通用任务机器东谈主不同,在医疗范畴,此类“幻觉”可能带来严重遵循 —— 若 Veo-3 类系统生成看似合理实则违背医学范例的操作视频,或将误导手术机器东谈主或医学生习得诞妄时期。
限定还标明,现时将视频模子视为“宇宙模子”(world models)的设思仍过于超前。现存系统仅能师法表不雅通顺与形态变化,却无法可靠掌捏剖解结构、生物力学及手术中的因果逻辑。其输出视频虽具名义劝服力,实则无法捕捉手术背后确切的生理机制与操作逻辑。
告白声明:文内含有的对外跳转敞开(包括不限于超敞开、二维码、口令等样式),用于传递更多信息,神圣甄选时期,限定仅供参考,IT之家总计著作均包含本声明。
]article_adlist-->
声明:新浪网独家稿件,未经授权贬抑转载。 -->
天元证券_天元证券开户_诚信运营!_天元证券提示:本文来自互联网,不代表本网站观点。




